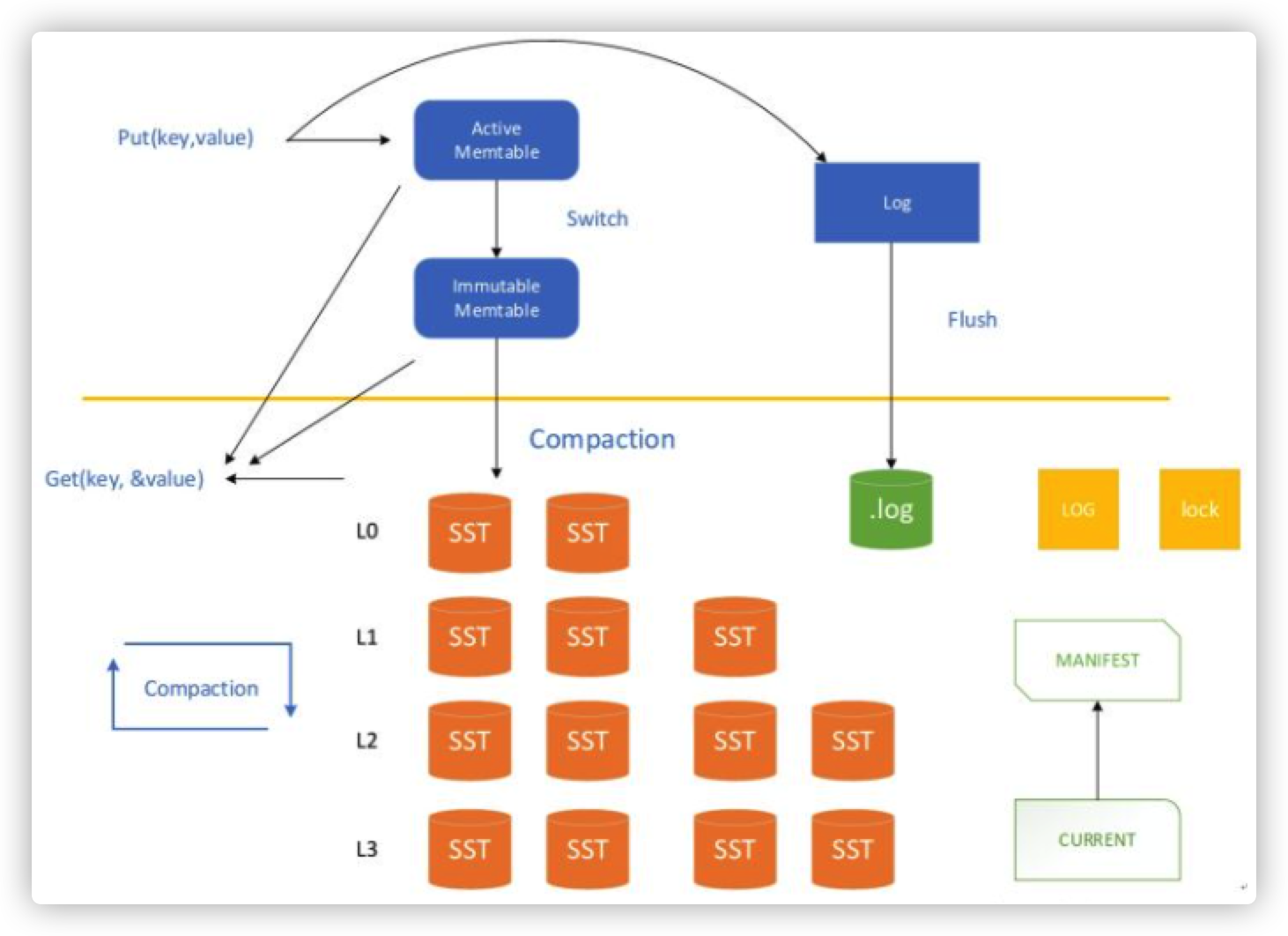
结构
- MemTable:内存数据结构,具体实现是 SkipList。 接受用户的读写请求,新的数据会先在这里写入。
- Immutable MemTable:当 MemTable 的大小达到设定的阈值后,会被转换成 Immutable MemTable,只接受读操作,不再接受写操作,然后由后台线程 flush 到磁盘上 —— 这个过程称为 minor compaction。
- Log:数据写入 MemTable 之前会先写日志,用于防止宕机导致 MemTable 的数据丢失。一个日志文件对应到一个 MemTable。
- SSTable:Sorted String Table。分为 level-0 到 level-n 多层,每一层包含多个 SSTable,文件内数据有序。除了 level-0 之外,每一层内部的 SSTable 的 key 范围都不相交。
- Manifest:Manifest 文件中记录 SSTable 在不同 level 的信息,包括每一层由哪些 SSTable,每个 SSTable 的文件大小、最大 key、最小 key 等信息。
- Current:重启时,LevelDB 会重新生成 Manifest,所以 Manifest 文件可能同时存在多个,Current 记录的是当前使用的 Manifest 文件名。
- TableCache:TableCache 用于缓存 SSTable 的文件描述符、索引和 filter。
- BlockCache:SSTable 的数据是被组织成一个个 block。BlockCache 用于缓存这些 block(解压后)的数据。
写逻辑
- 将key-value封装成WriteBatch;
- 循环检查当前DB的状态,确定策略(DBImpl::MakeRoomForWrite()):
- 如果当前L0层的文件数目达到了kL0_SlowdownWritesTrigger(8)阈值,则会延迟1s写入,该延迟只发生一次;
- 如果当前memtable的size未达到阈值write_buffer_size(默认4MB),则允许写入;
- 如果memtable的size已经达到阈值,但immutable memtable仍然存在,则等待compaction将其dump完成;
- 如果L0文件数目达到了kL0_StopWritesTrigger(12),则等待compaction memtable完成;
- 上述条件都不满足,则memtable已经写满,并且immutable memtable不存在,则将当前memetable置成immutable memtable,产生新的memtable和log file,主动触发compaction,允许该次写。
- 设置WriteBatch的SequenceNumber;
- 先将WriteBatch中的数据写入log(Log::AddRecord());
- 然后将WriteBatch的数据写入memetable,即遍历WriteBatch解析出key/value/valuetype,Delete操作只写入删除的key,ValueType是KTypeDeletion,表示key以及被删除,后续compaction会删除此key-value。
- 更新SequenceNumber(last_sequence + WriteBatch::count())。
为了提高写入效率,LevelDB会把多个写线程提交的key-value封装成一个WriteBatch一次性写入。WriteBatch的结构如图3中WriteBatch所示。
用户的数据写入到log日志后,还要写入一个memtable的结构中,LevelDB利用skiplist实现了memtable,在memtable内key是有序的。immutable memtable与memtable结构是一样的,只提供读不允许写入。用户的数据已经封装在WriteBatch中,在插入memtable时,需要遍历WriteBatch,decode每个key-value。在memtable中,key-value的格式如下:
读逻辑
- 如果ReadOption指定了snapshot,则将snapshot的Sequence Number作为最大的Sequence Number,否则,将当前最大的Sequence Number(VersionSet::last_sequence_number)作为最大的Sequence Number。
- 在memtable中查找(Memtable::Get())。
- 如果在memtable中未找到,并且存在immutable memtable,就在immutable memtable中查找(Memtable::Get())。
- 如果(3)仍未找到,在sstable中查找(VersionSet::Get()),从L0开始,每个level上依次查找,一旦找到,即返回。
- 首先找出level上可能包含key的sstable,FileMetaData结构体内包含每个sstable的key范围。
- L0的查找只能顺序遍历每个file_0,因为L0层的sstable文件之间可能存在重叠的key。在L0层可能找到多个sstable。
- 非L0层的查找,对file_[i]基于FileMetaData::largest做二分查找即可定位到level中可能包含key的sstable。非L0上sstable之间key不会重叠,所以最多找到一个sstable。
- 如果该level上没有找到可能的sstable,跳过,否则,对要进行查找的sstable获得其Iterator,做seek()操作。
- seek()成功检查有效性,依据ValueType判断是否是有效的数据:
- kTypeValue: 返回对应的value数据。
- kTypeDeletion: 返回data not exist。

sstable文件由data block、meta block、metaindex block、index blcok和footer组成。默认大小2MB。
- data block: key-value存储部分,按key有序排列,data block内部的格式如图7左侧。LevelDB采用了前缀压缩,每16个- key-value记录一次重启点restart。data block默认大小4KB。
- meta block:存储key-value的filter,默认是bloom filter。
- metaindex blokc: 指向meta block的索引。
- index block:指向data block的索引。
- footer: 索引metaindex block 和 index block。
如果数据不在内存中的组件中,那就需要在磁盘的sstable文件中查找了,基于B+树思想的存储引擎,利用索引可以直接定位到具体的哪个磁盘块,而LSM树的存储引擎需要遍历多个sstable文件才能确定数据在哪个磁盘块,读性能自然就不如B+树了。在介绍如何在磁盘上查找含有指定Key的sstable之前先介绍一个重要的数据结构:
struct FileMetaData {}
1、先定位key可能在哪些sstable文件中。这里的定位利用了上面的FileMetaData结构体里的smallest、largest字段,如果在这个范围里,该文件的FileMetaData加入一个vcetor tmp保存,每一层有很多的sstable文件,而且key可能存在多个版本,所以tmp里面可能存在很多sstable文件,如何确定最新的版本在哪个文件里呢?查找的原则应该是先从最新的sstable文件中查找,对于L0层,LevelDB做了优化,这里要说明一下,sstable文件是用uint64_t number命名的,而且越新的数据number越大,所以vector tmp按照FileNumber排序。非L0层的sstable文件之间key不会重叠,所以可以利用二分查找定位sstable。
2、在第一步定位了key可能存在的sstable之后,第二步需要定位key在sstable文件的哪个data block里面,图9的sstable格式里有一个重要的模块:index block。index block存储了data block的索引,为了加速读性能,leveldb也做了优化,把经常访问的sstable的index block缓存在cache中,关于cache的知识点后续会介绍。利用index block可以快速定位key可能存在哪个data block中。如何确定key到底在不在data block呢,LevelDB利用bloom filter,如果通过bloom filter得出key不在此data block中,那么该key 肯定不在此data block中,则data not found;如果通过bloom filter得出key在此data block中,还不能完全肯定在此data block中,还需要去遍历该data block